Get Access to free PDF

Unlock the Power of Prompt Engineering 101
Master the art of prompt engineering and supercharge your AI projects with our comprehensive guide. Learn the secrets behind crafting effective prompts.

Master the art of prompt engineering and supercharge your AI projects with our comprehensive guide. Learn the secrets behind crafting effective prompts.
%20%26%20Content%20Storage.png)
If you’ve ever asked ChatGPT a question and thought, “That sounds polished… but not quite accurate,” you’ve met the limits of traditional large language models (LLMs).
Enter Retrieval-Augmented Generation (RAG) — the technology that’s quietly revolutionizing how AI works behind the scenes.
RAG bridges the gap between a model’s general knowledge and your specific, up-to-date information. It allows AI to pull relevant facts from trusted sources before generating an answer — making it smarter, more accurate, and more useful than ever.
In short: RAG turns AI from a “know-it-all” into a “research assistant” who actually checks the facts first.
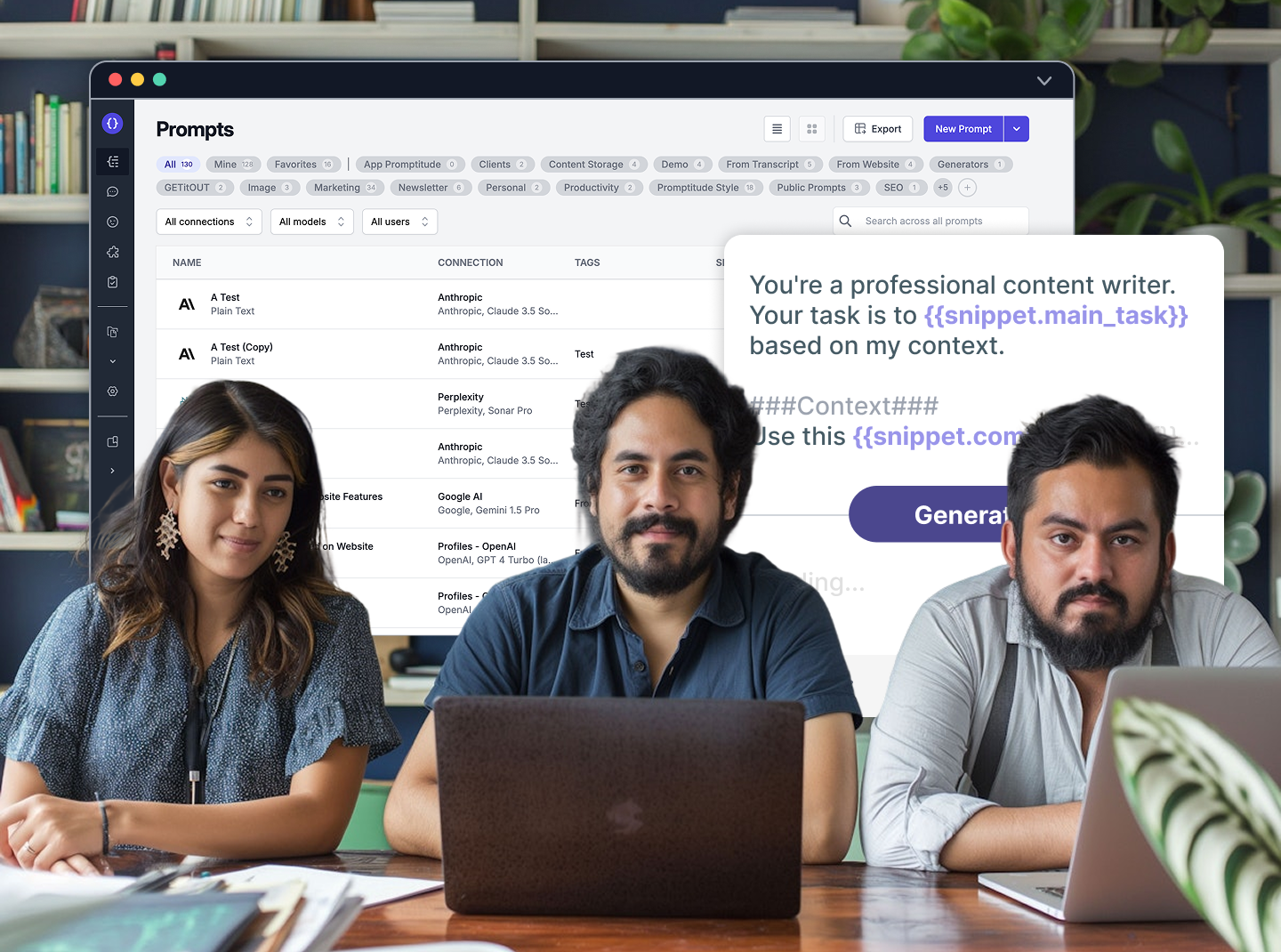
In Promptitude, at the heart of this transformation lies Content Storage — a powerful layer that gives RAG access to your own business knowledge. By connecting AI to your documents, databases, and internal resources, Content Storage lets you build reliable, context-aware outputs that reflect your organization’s expertise. Together, RAG and Content Storage form the foundation of next-generation AI solutions — from personalized content creation and automated reporting to intelligent customer support and business decision-making.
In this quick guide, we’ll explore what Retrieval Augmented Generation is, how it works, why it matters for modern organizations, and how platforms like Promptitude make it possible to implement RAG without technical complexity.
Retrieval-Augmented Generation (RAG) is an AI framework that combines two capabilities:
Unlike a standard LLM, which relies solely on its training data (and may be outdated or incomplete), RAG systems stay current — pulling in the latest company policies, product specs, research papers, or customer FAQs right before generating text.
This approach ensures that AI answers are not only fluent but also factually grounded and organization-specific.
Here’s a simplified look at what happens under the hood:
This creates a feedback loop of intelligence: the model writes with knowledge instead of guessing from memory.
.png)
To help you navigate the world of AI and Retrieval-Augmented Generation, we’ve compiled a concise glossary of key terms. Understanding these concepts will make it easier to grasp how RAG works, what components are involved, and how to implement it effectively — whether you’re a content creator, marketer, or AI enthusiast.
Traditional AI can sound convincing — but it often hallucinates.
RAG solves this by grounding outputs in real, verifiable information. Beyond improving accuracy, RAG offers significant business value:
The implementation of RAG in 2025 is already showing a notable impact on businesses, improving both decision-making and operational efficiency. From accelerating data integration to improving productivity, RAG enables organizations to automate data extraction and analysis with more accurate and contextually relevant results. This not only optimizes infrastructure costs but also speeds up the time to gain insights, enabling faster, data-driven decision-making (Squirro, Microsoft).
Companies across all sectors are adopting RAG to improve decision-making processes, reduce costs, and increase customer satisfaction. For example:
According to Forrester, RAG-enabled systems “provide contextually rich and accurate responses to customers, reducing reliance on human agents.”
In short, RAG represents a powerful tool for businesses, providing access to relevant, up-to-date data without the limitations of traditional language models. Promptitude.io exploits this potential through its Content Storage feature, offering a simple and effective solution for teams and organizations seeking to maximize intelligent content generation capabilities.
Implementing RAG typically involves several moving parts. Here’s a breakdown of the architecture:
This stack allows the system to take any question, search your data, and produce a response enriched with context — all in seconds.
Setting up RAG from scratch usually requires data pipelines, vector indexes, and fine-tuned embeddings.
But Promptitude changes that — by letting anyone implement RAG without technical expertise.
Using its Content Storage feature, Promptitude turns RAG into a plug-and-play capability.
Here’s how it works:
Promptitude’s Content Storage feature acts as a central hub for your documents, PDFs, and other knowledge assets. This allows RAG to work efficiently without complicated technical setups.
.png)
Within Promptitude, the entire RAG (Retrieval-Augmented Generation) process happens in two automated steps that make your content instantly usable in AI workflows:
Once this step is complete, your content is indexed and ready to be queried — no coding or manual setup required.
The result is a context-enriched prompt — your AI now “knows” your company knowledge, documents, and internal materials before answering.
And for full transparency, you can see exactly which chunks were retrieved after generation to verify that the response was built on the right content.
.png)
Promptitude provides transparency and control. You can see exactly which chunks of content were used to generate each answer, set similarity thresholds, limit the number of retrieved passages, and organize your content via folders and tags. This makes RAG implementation both powerful and easy to manage, allowing teams to scale their knowledge bases and maintain accuracy without any coding.
Learn more in the Promptitude Content Storage Guide
No coding. No Pinecone setup. No retriever scripting. Just switch on context retrieval — and Promptitude does the heavy lifting behind the scenes.
Key Benefits of Promptitude Content Storage:
You can fine-tune RAG behavior with intuitive settings:
This flexibility ensures your AI delivers precise, brand-consistent, and contextually accurate results every time.
Implementing RAG effectively requires more than just uploading data — it’s about structuring, maintaining, and monitoring your knowledge sources. Following best practices ensures your AI outputs are accurate, consistent, and scalable.
Even the most advanced AI system will produce suboptimal results if the underlying data or workflow isn’t managed correctly. By following RAG best practices, you can maximize accuracy, speed, and relevance — while maintaining a consistent knowledge base for your team:
RAG is becoming the backbone of enterprise AI — powering everything from chatbots and customer support systems to marketing automation and analytics. Businesses and developers can expect even more intelligent, efficient, and integrated solutions in the coming years, unlocking the next generation of AI-assisted knowledge work.
Future developments will likely include:
As the AI ecosystem matures, RAG will be the standard way to keep large models both powerful and trustworthy.
Promptitude is already enabling this future by simplifying content storage, retrieval, and RAG implementation — making these advanced features accessible without technical expertise. Teams can scale knowledge bases, automate context retrieval, and produce accurate AI outputs across marketing, customer support, research, and internal operations.
Retrieval-Augmented Generation represents the missing link between language models and real-world data.
It ensures your AI doesn’t just talk well — it knows what it’s talking about.
With no-code solutions like Promptitude, you can now bring the power of RAG into your business workflows in minutes, not months — and finally bridge the gap between knowledge and intelligence.


Easily incorporate advanced generative AI into your team, product, and workflows with Promptitude's plug-and-play solutions. Enhance efficiency and innovation effortlessly.
Sign Up Free & Discover NowExperience the perfect AI solution for all businesses. Elevate your operations with effortless prompt management, testing, and deployment. Streamline your processes, save time, and boost efficiency.
Unlock AI Efficiency: 50k Free Tokens