Get Access to free PDF

Unlock the Power of Prompt Engineering 101
Master the art of prompt engineering and supercharge your AI projects with our comprehensive guide. Learn the secrets behind crafting effective prompts.

Master the art of prompt engineering and supercharge your AI projects with our comprehensive guide. Learn the secrets behind crafting effective prompts.

In the fast-paced world of AI-driven content creation, generic responses no longer cut it. Businesses need AI that speaks in their unique voice, understands their brand, and delivers up-to-the-minute, personalized content. Enter Retrieval-Augmented Generation (RAG) – the game-changer in AI personalization.
Retrieval-Augmented Generation (RAG) is a sophisticated AI technique that pairs a retrieval model with a generative language model. The retrieval model first fetches relevant information from a vast dataset or knowledge base. This information is then used by the generative model to craft responses that are not only pertinent but also deeply contextualized.
Retrieval-Augmented Generation (RAG) operates by enhancing AI responses with real-time, relevant data. When a query is received, RAG first searches a curated database of external information, converting the query into a vector representation for comparison. It then retrieves the most relevant data and integrates it into the AI's prompt. This augmented prompt is fed into a Large Language Model (LLM), which generates a response that's not only linguistically coherent but also grounded in up-to-date, contextually relevant information.

The process ensures that AI outputs are accurate, timely, and tailored to specific needs, significantly improving the quality and reliability of AI-generated content.
Let's break down its sophisticated mechanism:
RAG begins by establishing a rich knowledge base outside the AI's original training data. This external data can come from various sources like APIs, databases, ordocument repositories, and exist in multiple formats (files, database records, or long-form text). Using a technique called language model embedding, this diverse data is converted into numerical representations and stored in a vector database, creating a comprehensive, AI-comprehensible knowledge library.

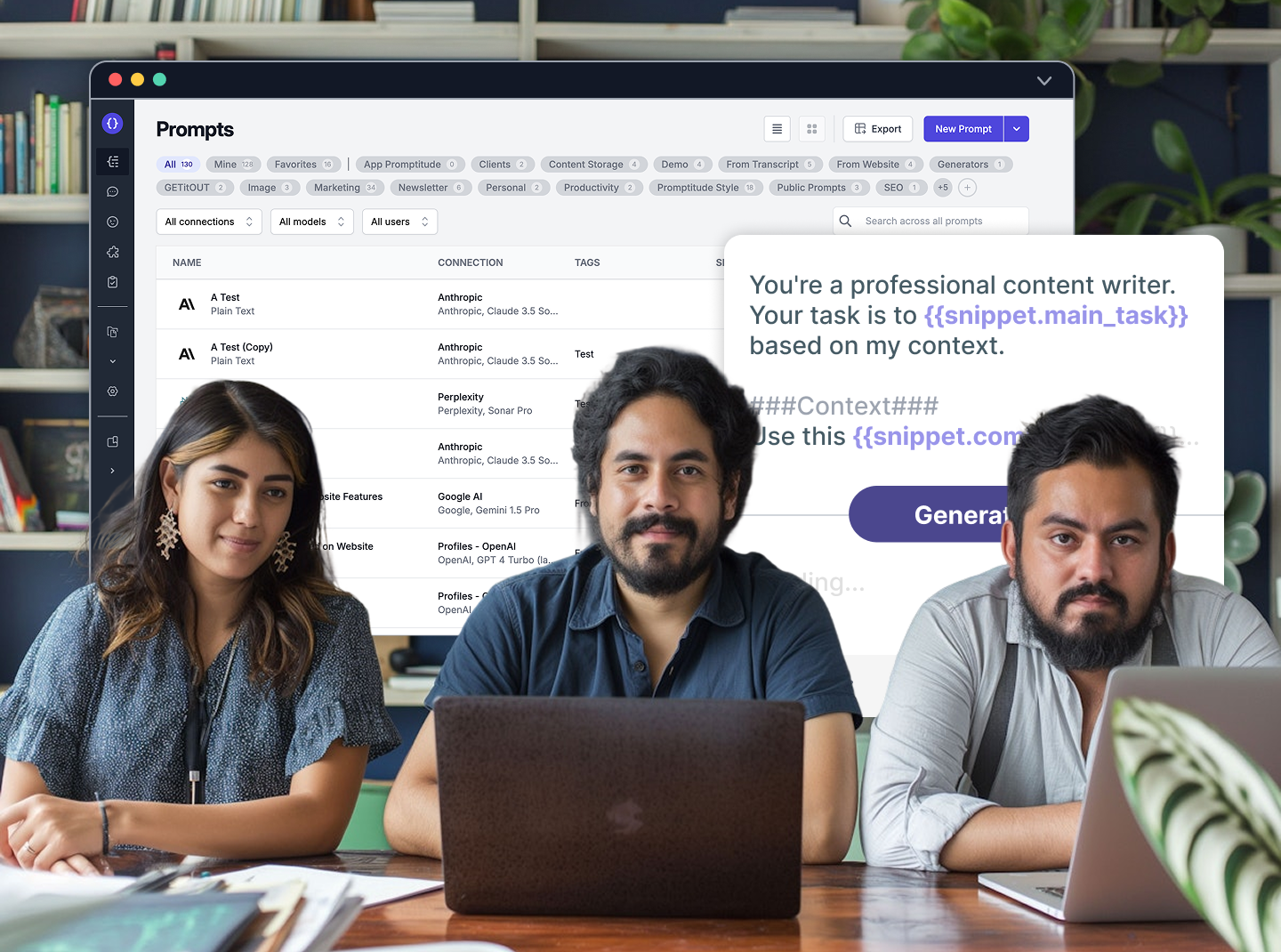
Promptitude streamlines the data creation process through its Content Storage feature. This unified space manages a wide array of document formats, allowing easy uploads via browser and even web scraping of your website. This centralized repository houses both your prompts and content, simplifying data management. The information undergoes processing using OpenAI Embedding and is then securely stored in Pinecone, a leading vector database, ensuring your data is both accessible and protected.
When a user inputs a query, RAG initiates a relevance search. The user's query is transformed into a vector representation and compared against the vector database. This relevance is determined through mathematical vector calculations and representations.

Initiating relevant searches in Promptitude is seamlessly integrated into your workflow. Whether you're using prompts or engaging in chats, simple functionalities like the "Add Context" switch or including Content Storage input variables trigger this process. This user-friendly approach ensures that relevant information is always at your fingertips, enhancing the quality and specificity of your AI interactions.
RAG then enhances the user's input by contextually incorporating the retrieved relevant data. This crucial step employs prompt engineering techniques to effectively communicate with the Large Language Model (LLM). The augmented prompt enables the LLM to generate a precise response to the user's query, grounded in the most up-to-date and relevant information.

Promptitude's "Add Context" functionality simplifies the process of enhancing your prompts with relevant information. With just a few clicks, you can augment your prompts without needing expert knowledge or technical configurations. This streamlined approach democratizes the use of advanced AI techniques, making it accessible to users regardless of their technical expertise.
The LLM processes the augmented prompt, which now includes both the original query and the relevant retrieved information. It then generates a response that's not only coherent but also accurately reflects the most current and pertinent data available.

Promptitude's flexibility shines in the response generation phase. By allowing connections to various AI providers, it enables you to generate consistent results across different models. This feature empowers you to compare and contrast the quality and speed of various AI models while maintaining coherence in your outputs, ensuring you always have the best tool for your specific needs.
In essence, RAG creates a dynamic synergy between vast language models and current, specific data sources. This synergy results in AI responses that are not only linguistically proficient but also contextually accurate and up-to-date, marking a significant advancement in AI-powered information retrieval and generation.
Leveraging Pinecone’s vector database in our RAG implementation, Promptitude ensures data reliability and up-to-dateliness without compromising security. With comprehensive data protection measures and compliance with key regulations (SOC2, HIPAA, GDPR), you can trust that your sensitive information remains secure and confidential.
Ready to revolutionize how your business utilizes AI? Try Promptitude’s Content Storage today and see the difference retrieval-augmented generation can make in delivering bespoke AI solutions tailored just for your brand.
As you integrate RAG into your AI applications, the potential to drive more personalized and meaningful interactions with your customers is vast. With Promptitude, moving beyond basic generative models to a more dynamic, data-driven approach is not just possible—it’s simple and secure.


Easily incorporate advanced generative AI into your team, product, and workflows with Promptitude's plug-and-play solutions. Enhance efficiency and innovation effortlessly.
Sign Up Free & Discover NowExperience the perfect AI solution for all businesses. Elevate your operations with effortless prompt management, testing, and deployment. Streamline your processes, save time, and boost efficiency.
Unlock AI Efficiency: 50k Free Tokens